Case Study
“Alone we can do so little; together we can do so much.” - Helen Keller
Introduction
Symphony is an open source framework designed to make it easy for developers to build collaborative web applications. Symphony handles the complexities of implementing collaboration, including conflict resolution and real-time infrastructure, freeing developers to focus on creating unique and engaging features for their applications.
In this case study, we’ll discuss the challenges that arise when building collaborative experiences on the web, the limitations of traditional approaches in solving these problems, and how we designed Symphony to overcome them.
Collaboration
Real-time collaboration, where multiple users can concurrently work together on a common task, has been a notable feature since the earliest days of the internet. It’s origin can be traced back to the 1960s, when Douglas Engelbart in his famous Mother of All Demos, demonstrated the first real-time collaborative editor, built on the oN-Line System (NLS), that allowed users to create and edit documents, link them together, and share them with others.1
However, for much of the web’s history, the majority of applications have notably been non-collaborative. Without the ability to work together on a common task in real-time, users have to instead enter into a tedious cycle of changing, exporting, and manually syncing or emailing copies of files.

This slow feedback loop harms productivity.2 In other words, this workflow is sub-optimal and restrictive.
With the rise of remote work where users are geographically separated, the need to improve this workflow has become even more acute.
As noted by industry leaders, the optimal solution is for applications to allow multiple users to collaborate online in real-time.
"[Real-time collaboration] eliminates the need to export, sync, or email copies of files and allows more people to take part in the design process." - Evan Wallace, Figma
Popular products such as Figma, Google Docs, and Visual Studio Code, incorporate this as a defining feature, allowing multiple users to concurrently modify the same state.
The problem is that building these types of applications is non-trivial. To understand why, we need to consider the characteristics of traditional web applications.
Evolution of Web Applications
Traditionally, the architecture of most web applications have conformed to the client-server model, where client and server communicate in a request-response cycle.
When a user makes a change to the client state, the change is propagated to the application server via a HTTP request, which in turn updates the database i.e. the true application state and confirms the change to the client via a response.
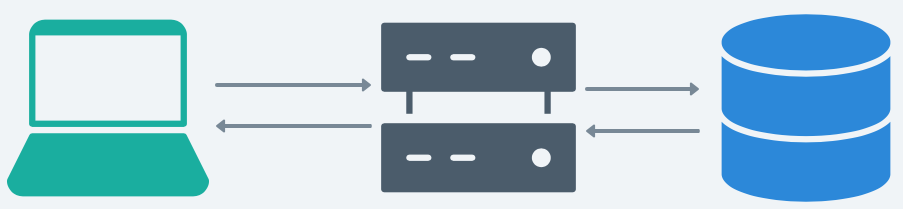
This architecture is fine for applications that are designed to be used by only one user at a time. However, for applications that seek to provide a multiplayer experience, the stateless nature of HTTP is problematic.
Since each state change by a given client is scoped to the request-response cycle, other users who wish to view the change must first request the data from the server, usually by refreshing the page.
In situations where multiple users are frequently modifying the same state, the need for each client to constantly send requests can quickly become burdensome and inefficient.
Introducing Real-Time
As companies began wanting to create applications that allowed multiple users to interact in realtime, the stateless nature of HTTP request-response cycle became a limitation. These applications such as online games, chat rooms, and social media platforms, needed to maintain updated state without requiring the user to take any specific action such as a page refresh. In other words, a different approach to data transmission was needed- one that allowed data to be shared bi-directionally between clients and/or a server in real-time.
In response, new web protocols were developed to help facilitate this. Two of the most popular include WebRTC and WebSocket.
WebRTC
Web Real-Time Communication (WebRTC) is an open-source technology that enables real-time communication between web browsers over the internet.3 The protocol uses a combination of JavaScript APIs and peer-to-peer networking to establish direct communication channels between browsers, without the need for a permanent, central server. UDP is used as the primary transport protocol for real-time data transmission. This makes WebRTC an especially attractive choice for collaborative applications that require very low-latency communication at the expense of reduced reliability and error correction, such as video conferencing, online gaming, and live streaming.
WebSocket
WebSocket is a web protocol that provides a persistent, bi-directional communication channel between a client and a server over a single, long-lived TCP connection.4 The connection is established via a handshake between client and server. Since TCP is used as the primary transport protocol, WebSocket is a suitable choice for collaborative applications that require stronger guarantees on the reliability and security of the communication channel at the expense of higher latency, such as real-time dashboards, stock price tickers, and live chat.
Using technologies such as WebRTC and WebSocket, clients and/or servers are able to maintain persistent, stateful communication channels, no longer bound by the limits of the request-response cycle. As such, it permitted the development of so-called real-time applications to be built, where state updates are perceived to be received instantaneously without page refresh.
It may initially seem that the addition of real-time solves the collaboration problem since multiple users can now see changes immediately.
This is not the case.
The problem is that many real-time applications such as chat applications have the implicit constraint that each piece of state can only have a single mutable reference to it. In other words, the same piece of state cannot be modified concurrently by multiple users. For example, in a chat application, a given message is owned by a single user and they alone can edit it at any given time.
For an application to be truly collaborative, it must allow users to work together in real-time on shared state, where multiple users can modify the same piece of state at the same time, without conflicts or inconsistencies.
The possibility of conflict radically increases the complexity of implementing collaborative applications.
Conflict
In the context of real-time collaborative applications, conflict refers to a situation where two or more users attempt to modify the same piece of state, without knowledge of one another (concurrently), resulting in conflicting versions of that data.
For example, multiple users working on a shared task or document may make changes to the same part of the document at the same time. Alternatively, network delays could cause state to diverge between different users which must be reconciled.
We can concretely demonstrate how conflict arises using the following examples.
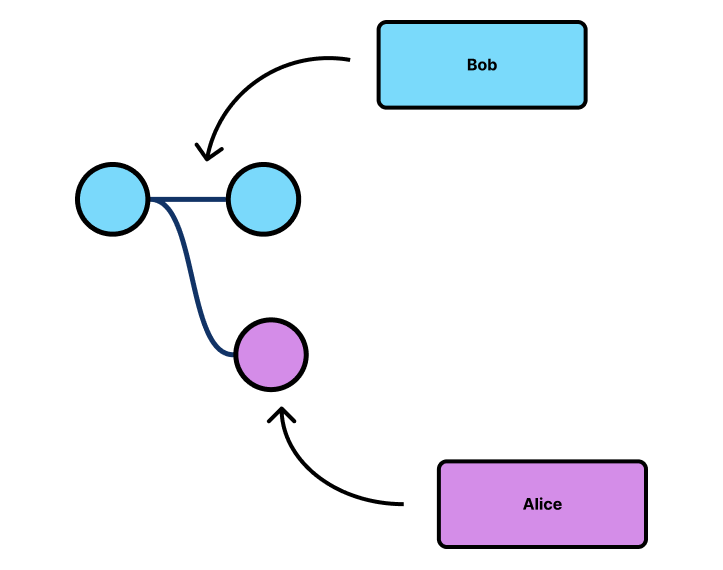
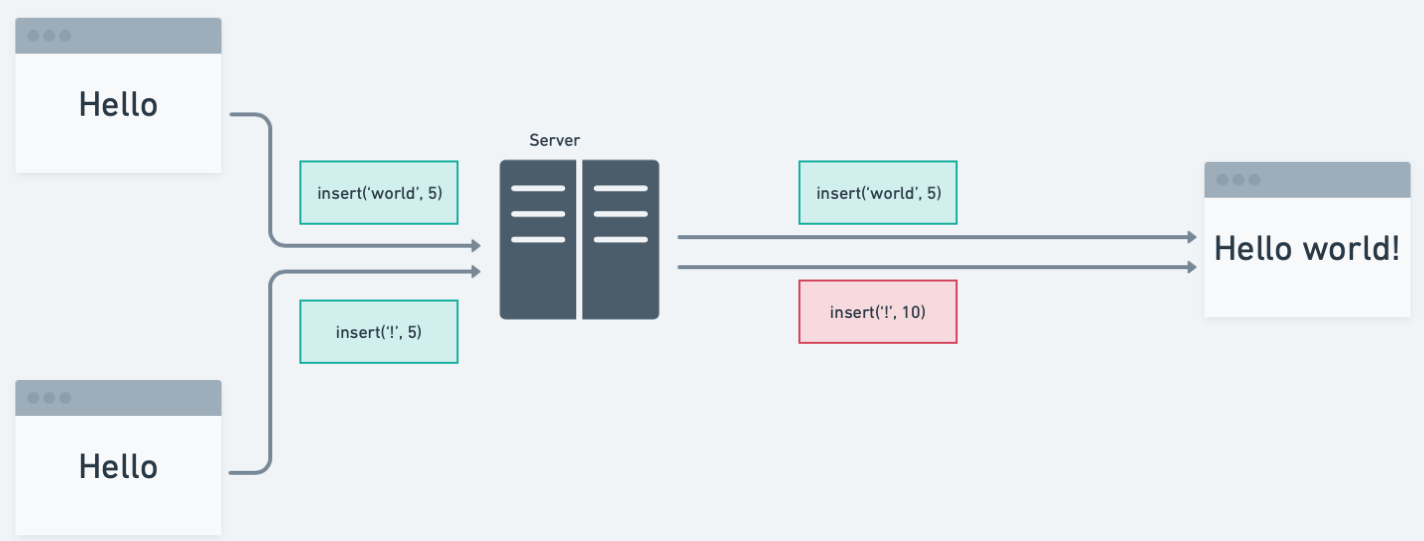
Suppose that Alice and Bob are collaborating on a text document, when both Bob and Alice attempt to write at the same spot:
When conflicts arise, Alice and Bob’s modifications can be seen as branching off from the previous state of the system, creating a parallel version of the application state.
For a collaborative application, we need a method of reconciling such conflicts and enforcing distributed consistency across clients.
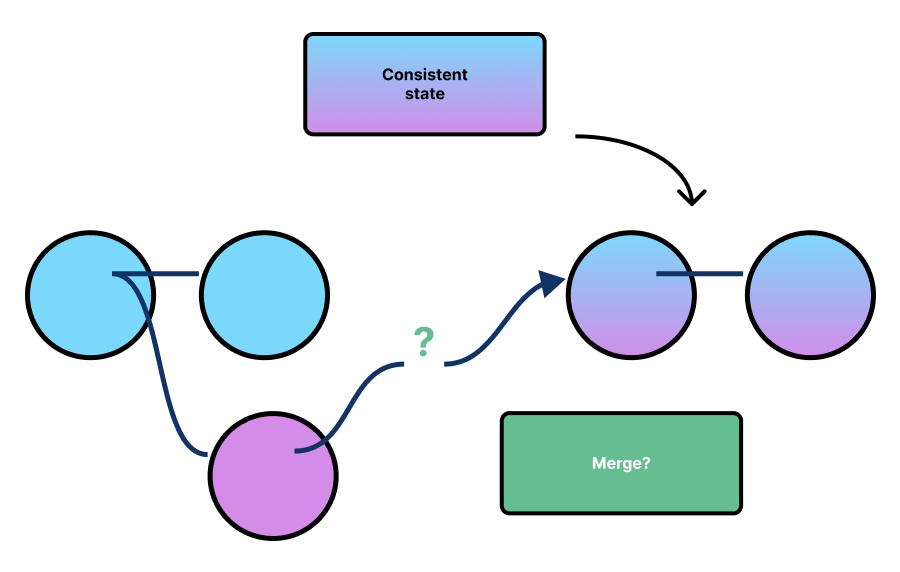
In other words, after applying all state changes, the application should deterministically converge to an eventually consistent state across the whole system that all parties agree upon.
Methods of Conflict Resolution & Maintaining Distributed Consistency
Over the years, there have been multiple solutions that have been proposed to the problem of conflict resolution.
The simplest strategy, as mentioned previously, is to prevent conflicts from occurring in the first place. This can be implemented via locking. When a given user is making edits, the document is locked, becoming read-only to other users. In other words, we impose the constraint that only a single user can have a mutable reference to the document at any given time.
Thanks to its simplicity, this approach is widely used even today. For example, Basecamp, a web-based project management tool, employs locking to prevent conflicts:
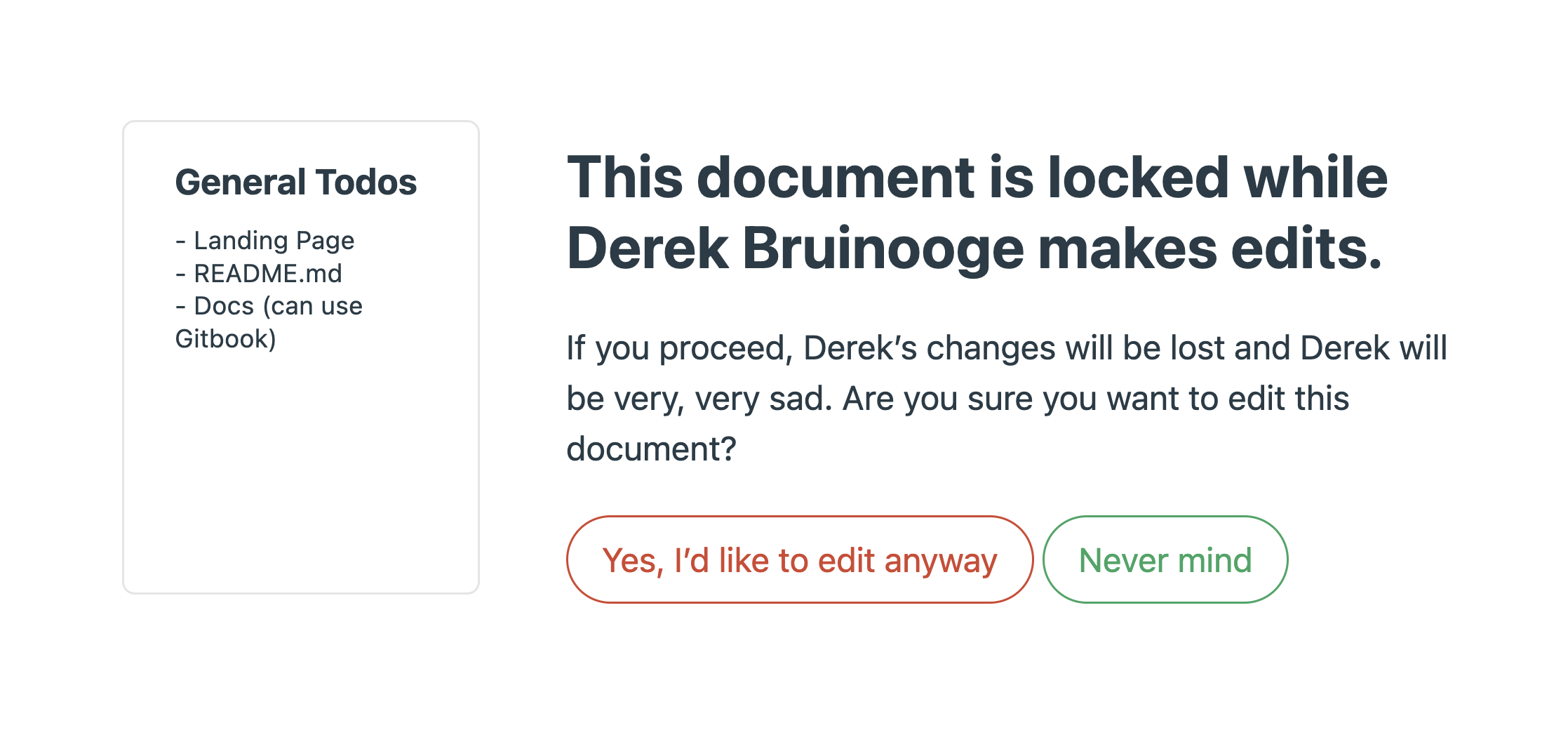
However, as noted previously, this approach provides a very limited workflow since it solely facilitates asynchronous collaboration, where users have to implicitly arrange times when they can edit the document or work on separate documents and then merge changes.
For real-time, synchronous collaboration, more advanced conflict resolution mechanisms are required.
Operational Transformation (OT)
One possible approach is to use the operational transformation (OT) algorithm, famously used by Google Docs 5.
OT represent each user’s edits as a sequence of operations that can be applied to the shared application state. For example, in the case of a collaborative text editor, where the sequence of characters is zero-indexed, the operation to insert the character 'a' at the beginning of the first sentence may be represented as insert('a', 0).
When a client makes an edit to the state, the corresponding operation is transmitted to the server, which broadcasts it to all other collaborating clients.
In cases where multiple users attempt to modify the same piece of state concurrently, the OT algorithm defines a set of rules, which encode how conflicting operations should be transformed such that the operations can be applied in any order, without causing conflict.
For example, in the case of the collaborative text editor, two clients may attempt to concurrently insert text at the start of the document i.e. O1 = insert('a', 0, 1) and O2 = insert('b', 0, 2), where the third argument represents the client id. The transform rule may be to shift one of the insertions to the right by the length of the other insertion i.e. insert('a', 0, 1) and T(O1) = insert('b', 1, 2).
This ensures that both insertions can be applied whilst still capturing user intent and not modifying the intended meaning of the document.
Since OT only requires operations to be incrementally broadcast, the algorithm is efficient and has low memory overhead.
The problem is that OT is very complex to implement correctly. The OT algorithm assumes that every state change is captured, which in modern rich browser environments, can be difficult to guarantee. Further, since operations have a finite transit time to the server, the states of clients naturally diverge over time from one another. The larger the divergence, the larger the number of possible combinations of operations that result in conflict, each of which must be accounted for by the transform rules. Since many of these conflicting combinations are very difficult to foresee, formally proving the correctness of OT is complicated and error-prone, even for the simplest of OT algorithms.
This sentiment is widely shared by practitioners in the field, as highlighted by Joseph Gentle, a former Google Wave engineer, and author of the ShareJS OT library, who said:
Unfortunately, implementing OT sucks. There's a million algorithms with different tradeoffs, mostly trapped in academic papers. […] Wave took 2 years to write and if we rewrote it today, it would take almost as long to write a second time.
In fact, 4 out of 8 different implementations of OT from the original 1989 paper to 2006 were found to be incorrect, missing subtle edge cases. The consequence of this incorrectness was that client state would irrevocably diverge, with no way to return to a consistent state.
The complexity of OT led researchers to find alternatives, the most promising of which are conflict-free replicated data types, or CRDTs.
Conflict Free Replicated Data Types (CRDTs)
A conflict-free replicated data type (CRDT) is an abstract data type designed to be replicated at multiple processes.6 By definition, CRDTs have the following properties:
- Independent- Any replica can be modified without coordinating with other replicas.
- Strongly eventually consistent- When any two replicas have received the same set of updates (in any order), the mathematical properties of CRDTs guarantee that both replicas will deterministically converge to the same state.
By imposing these mathematical properties on the CRDT and it’s associated algorithms, clients can optimistically update their own state locally and broadcast their updates to all other remote, state replicas. Since CRDTs are strongly eventually consistent, upon a given remote replica receiving all updates, the remote replica is guaranteed to converge to the same state as the local replica without conflict.
The advantage of CRDTs is that they are guaranteed to be conflict-free, as long as the required mathematical properties are imposed. Since these mathematical properties are well-defined, it is easier to prove the correctness of a CRDT than any corresponding OT implementation. Further, since each replica is independent and that CRDTs make no assumption about the network topology, CRDTS are partition tolerant by default and can be used in a variety of network topologies including client-server and P2P. This property also means they are offline-capable by default.
However, the mathematical constraints of CRDTs, in particular that operations should be commutative adds some unavoidable overhead. Most commonly-used data structures do not have commutative operations by default. For example, the add and remove operations of a Set are not naturally commutative. To ensure commutativity, the CRDT must retain additional metadata.7
For example, in the case of the add and remove operations of a Set, tombstones are typically used as placeholders for removed entries- if a replica receives a remove operation for an element before it receives the add operation that actually added the element, the tombstone ensures that the remove operation is still correctly processed. Since the metadata must be retained for the required mathematical properties to be upheld, the use of CRDTs inevitably results in additional memory overhead, which can become significant for large state. As noted by Jospeh Gentle:
"Because of how CRDTs work, documents grow without bound. … Can you ever delete that data? Probably not. And that data can’t just sit on disk. It needs to be loaded into memory to handle edits." - Joseph Gentle, former Google Wave engineer
While recent research has sought to introduce garbage-collection methods to reduce the amount of metadata, there is still significant additional memory overhead when using CRDTs to represent a data model.
Custom Conflict Resolution Mechanisms
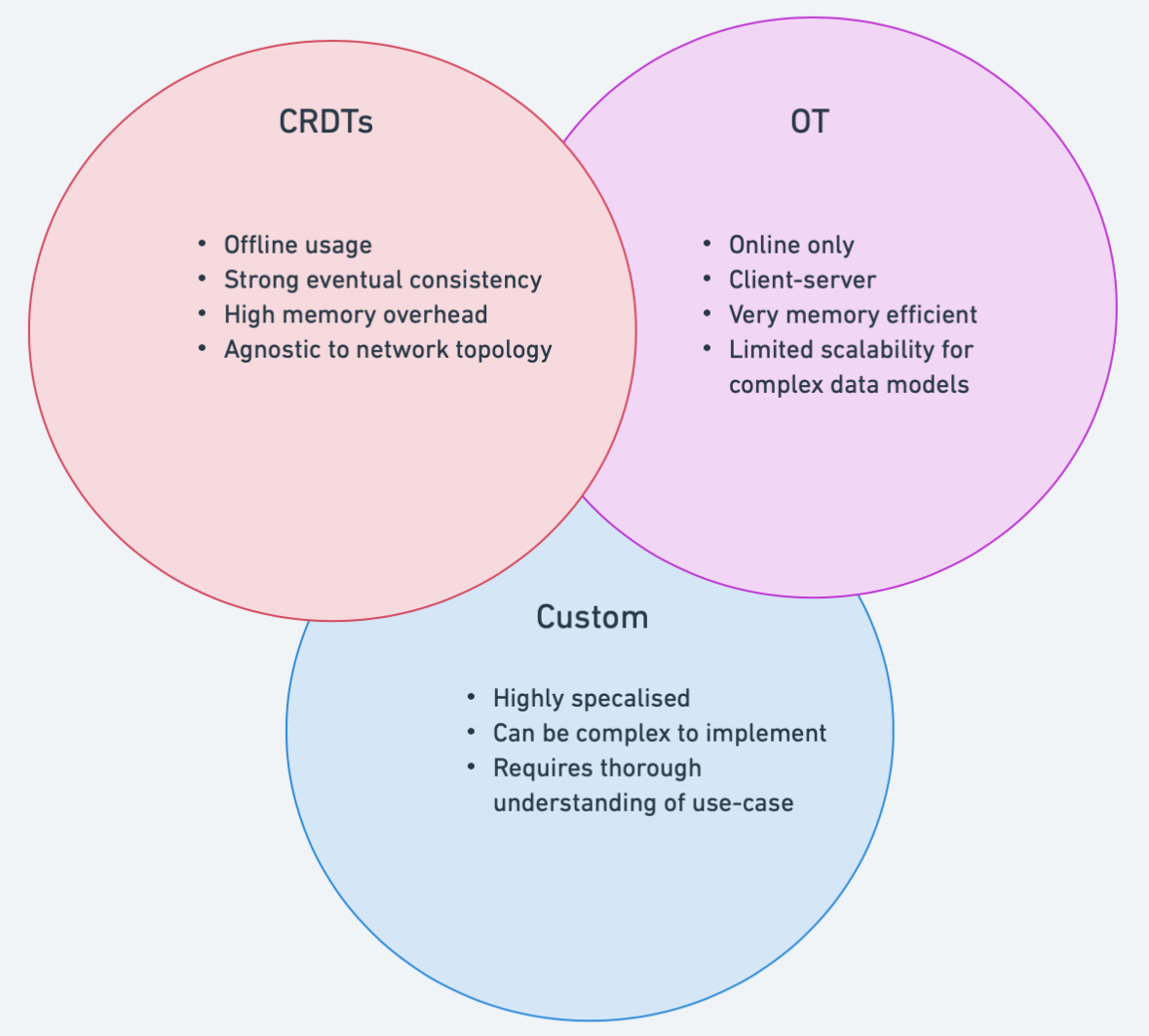
Whilst OT and CRDTs represent the most popular approaches to conflict-resolution, the complexity of OT and the memory overhead of CRDTs can sometimes be unacceptable for certain use-cases. As such, some choose to create custom, proprietary data models that are inspired by the OT and CRDT approaches and are highly specialised to a particular use-case.
For example, Figma relax many of the constraints imposed by CRDTs by adopting much simpler conflict-resolution semantics. In particular, they use simple last-write wins (LWW) semantics when two clients try to modify a value of a Figma object concurrently. This works great for Figma objects where changes are mutually exclusive i.e. a single value must be chosen, but would fail if used for text editing. In Figma’s case, this was a valid tradeoff for their use case but would not be a suitable model for other applications.8
The advantage of implementing a custom conflict-free data model is that the mechanism can be made highly-specialised to the target use-case. This can mean that many of the constraints that come with OT and CRDTs can be relaxed which may result in a simpler and efficient data representation. However, developing a custom model can be potentially risky since it requires a number of assumptions to be made about the use-case. In Figma’s case, for example, introducing text-editing may require significant changes to their current conflict-resolution semantics.
Choosing a Method of Conflict Resolution
When choosing a conflict-resolution mechanism, there is no single best, one-size fits all solution. Each conflict-resolution mechanism has it’s own set of tradeoffs and choosing a particular approach requires a deep understanding of the usage pattern of the target application.
Some aspects of the target application that should be considered include:
- What CAP (Consistency, Availability, Partition-tolerance) properties should the system have?
- What is the application architecture? Client-server? P2P?
- Is the system required to operate offline?
- Are there any system-level constraints including CPU/memory limits?
- Is the data model generic or highly specialised to a particular use-case?
Answering these questions influences the suitability of each conflict resolution mechanism to a specific use-case.
Manually Building a Real-time Collaborative Application
Building a collaborative application from scratch can be time-consuming and difficult, particularly when dealing with the intricacies of real-time infrastructure and conflict-resolution mechanisms. It means that creating rich, collaborative experiences on the web has traditionally only been open to companies with the human and financial resources to roll their own solutions.
For smaller teams of modest means, who may lack familiarity with these specialised topics, implementing such systems has remained out of reach.
Provided below is a sample list of tasks involved in creating a production-ready real-time collaborative web application:
As a result, solutions have started to emerge that lower this barrier.
Existing Solutions
Existing solutions typically fall into two categories: DIY solutions and commercial solutions.
DIY Solutions
For organisations who have complex, specialised requirements for their collaborative functionality or want to tightly integrate with existing infrastructure, a DIY solution might be the best fit. This involves manually synthesising the various components required for a real-time collaborative application.
There are numerous open-source libraries providing implementations of popular conflict-resolution algorithms- teams would likely need to research, choose, and integrate the solution that best fits their use case. Alternatively, a bespoke solution may be best suited for highly specialised applications.
For the real-time network and persistence layer which handles the propagation of updates to collaborating clients and/or server(s) and storing of state, one could use a backend-as-a-service such as Ably, Pusher, or PubNub or provision a custom implementation using open-source libraries like ws or PeerJS on cloud infrastructure.
Whilst the DIY approach offers a high degree of customisation, it does require developers to have a high-level of proficiency in the relevant technologies. Thus, less experienced teams might reach for a Software-as-a-Service (SaaS) product to help manage their collaborative functionality needs.
Commercial Solutions
The advent of commercial offerings providing Collaboration-as-a-Service is a relatively recent phenomenon.
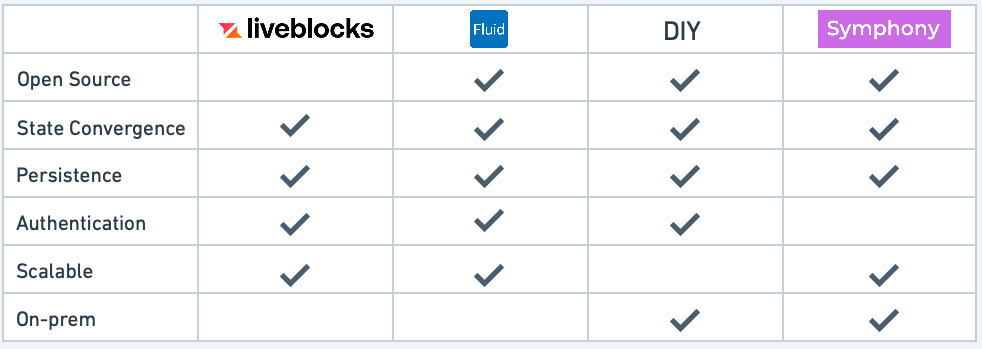
One of the most popular solutions, released in 2021, is Liveblocks. Whilst not as flexible as the DIY approach, Liveblocks provides a great developer experience, exposing all the components required for adding real-time collaboration to an application through an intuitive client API. This includes a collection of custom CRDT-like data types, autoscaling real-time infrastructure with persistence, and a developer dashboard for easily monitoring usage patterns. However, this convenience comes at a cost, with Liveblocks charging $299 per month for an application with up to 2000 monthly active users (MAU), valid as of September 2023.
A compelling alternative is Fluid Framework developed by Microsoft. Fluid provides a collection of client libraries that also expose custom CRDT-like distributed data structures. The client libraries connect to an implementation of the Fluid service, a runtime which handles the complexities of propagating updates in real-time and persisting state. Whilst Fluid is open-source, it provides a very limited implementation of the Fluid service by default, capable of handling only 100s of concurrent users. For larger applications, developers are forced to use either the Azure Managed Service or write a custom scaled implementation.
A Solution for Our Use Case
Looking at the above solutions, it is clear that until now, developers who want to incorporate collaboration into their products have been to partially or fully roll their own solutions or turn to a closed-source, managed provider.
The first option has significant implementation cost, particularly given that the expertise require to develop collaborative functionality is often orthogonal to the businesses’ core offering. The latter option suffers from vendor lock-in and can attract considerable expense, as noted with Liveblocks.
Following this, we wanted to build a tool for small teams that want to add collaborative functionality to their applications without having to spend time implementing and deploying their own conflict resolution and real-time infrastructure.
Further, we want to make our framework open-source, scalable and fully self-hosted so that developers have complete control of code and data ownership.
With globalisation and the rise of remote work, providing seamless web-native collaboration is no longer the preserve of the largest companies. Smaller teams increasingly want to reap the benefits of fast collaborative feedback loops in their products.
An example of this is Propellor Aero, who wanted the ability to collaborate with their customers on 3D interactive site survey maps.
“We started looking at building a service ourselves… We really didn't want to because it's a whole lot of work and it's a really difficult problem. This was a very new problem to us, our engineering team had different levels of experience in synchronisation in real-time as a whole.” - Jye Lewis, Engineering Manager, Propellor Aero
We sought to assist companies with similar profiles in adding collaborative functionality to their web application.
The availability of an open-source tool which handles the complexities of implementing collaboration, including conflict resolution and real-time infrastructure, would free Propellor Aero developers to focus on creating features that have direct business value, whilst still retaining control over all their data.
Symphony
Overview
Symphony is an open-source runtime designed to make it easy for developers to add collaborative functionality to their applications.
It comes with a client library that provides an intuitive API to a collection of conflict-free data types that are composed to construct a distributed data model. Symphony automatically provisions the required network infrastructure to propagate state changes to all collaborating clients in real-time and persist state between users sessions. It also provides real-time application- and system-level monitoring via a developer dashboard that exposes pertinent metrics including the number of active users, the size of persisted state (bytes), and the CPU/memory usage of each collaborative session.
Using Symphony
Symphony has been designed with ease-of-use in mind. In three simple steps, developers can create and deploy a real-time collaborative application.
After installing the required dependencies stated in the documentation, and globally downloading the Symphony CLI tool via npm:
- Run
symphony compose <projectName>. This command creates a newprojectNamedirectory, initializes a new Node project with the requiredpackage.json, and scaffolds some initial starter files including the Symphony configuration file,symphony.config.js. - Write and deploy the front-end client code by composing the collection of conflict-free data types provided by the Symphony client.
- Run
symphony deploy <domainName>, which deploys the application on Google Cloud Platform (GCP). After provisioning is complete, developers can runsymphony dashboardto view the developer monitoring dashboard.
Following these steps, developers can enhance existing their web applications with collaborative functionality using Symphony.
To illustrate this, here’s a simple whiteboard application where users can draw lines, shapes, and change colours. In it’s current form, the whiteboard is single-user and non-collaborative.
To make this whiteboard multiplayer, we modify the whiteboard code to make use of the conflict-free data types provided by the Symphony client. After deploying the application to GCP, user’s can now work together in the same collaborative space and see what others are doing in real-time.
We’ll now turn to how we built Symphony and the technical challenges we faced.
Architecture Overview
We’ll being by outlining the fundamental requirements we had to address and a description our design philosophy. We’ll then provide a high-level overview of our core architecture and discuss important design decisions, tradeoffs and improvements that were made.
Terminology
In order to express the system requirements accurately, we introduce some useful terminology:
- Document- refers to the shared state that clients modify during a session.
- Room- a collaboration session in which one or more clients connect to in order to modify the room document. A given room has a single document i.e. shared state that clients modify.
- Presence- represents the ephemeral state of a room which defines user’s movements and actions inside a room including cursor positions, user avatars, online/offline indicators, or any other visual representation that reflects the real-time activity or availability of users within the collaborative session.
Fundamental Requirements
When building our initial prototype, we focussed on the fundamental problems that needed to be solved in order to build the core of a real-time collaborative framework. These included:
- Deciding how to model the shared state of a room i.e. document, and selecting a suitable mechanism to resolve conflicts and understanding the constraints that such a choice would impose on the rest of our architecture.
- Determining how ephemeral and persistent state changes on one client would be propagated in real-time to all other subscribed clients and/or servers.
- Constructing a suitable persistence layer, where state can be stored between collaborative sessions and system metadata can be retained.
Design Philosophy
Symphony is designed with the principle that developers should be able to include collaboration into their products without having to radically modify their existing workflow and tools. With this as our guiding principle, we explain our choice of architecture and how it attempts to meet the fundamental requirements of a real-time collaborative framework.
Core Architecture
After some initial prototyping, we arrived at the following high-level flow on how a collaboration session involving multiple users starts, progresses and terminates.
A client connects to a server via WebSocket. The clients specifies the room to connect to by specifying the room ID in the URL path. The server extracts the room ID and queries the database to check if a room with that id already exists. If the id exists i.e. the room has been used before, the server retrieves the associated room document from storage and loads it into memory; otherwise, a new document is created in memory and a new room record created in the database.
Additional clients can connect to the active room and modify the state. Each update is propagated to the server which in turn updates the document state in memory and broadcasts it to all the other collaborating clients. Upon receiving updates, clients update their local state. When the last remaining client disconnects from the room, the document is serialized and written to storage. The document and room metadata is subsequently purged from memory, and the room is marked as closed in the database.
With an overall direction in mind, we then explored different options for each component of our core architecture.
Implementing the Core Architecture
Conflict Resolution
As mentioned previously, a key component of implementing real-time collaboration is the ability to deterministically reconcile conflicts, which arise as a result of multiple users concurrently modifying the same piece of state.
While we found that the performance and low memory overhead of OT was attractive, it’s complexity and the fact that it’s most suited to editing large text documents, made it less applicable to supporting generic data models.
For Symphony, we instead decided to use CRDTs as the primary conflict resolution mechanism. Their strong eventual consistency guarantees mean that client changes can be optimistically applied resulting in a faster user experience. In addition, they are highly available and fault-tolerant which means that the users can continue to change state even during network failure or disconnection- the state will simply synchronise with other clients upon reconnection.
Although CRDTs have traditionally suffered from inadequate performance and very large memory overhead, they have become exponentially faster and more memory efficient in recent years, thanks to an active research effort.9 To ensure suitable performance, we decided to use an operation-based CRDT, which unlike state-based CRDTs, only propagate operations over the wire instead of the entire state. The tradeoff is that operation-based CRDTs require a reliable network channel which could be easily included given our chosen network topology (see below).
For our collection of CRDTs, we chose to use Yjs, a library which provides a collection of generic, operation-based CRDT implementations based on the YATA algorithm. We chose Yjs since it had strong community support, has a very efficient linked-list data model with optimisations such as a garbage collector, making it one of the most memory-efficient and performant implementations. It also provided defined synchronisation and awareness protocols to propagate across persistent and ephemeral updates across a generic network layer.
We also considered using Automerge, the other leading open-source offering in this space. Whilst equally performant, it is less mature and was 2x less memory efficient than Yjs in recent benchmarks.
State Change Propagation
Since we now have a collection of conflict-free data types that can be used to construct a distributed data model, we need to consider how to propagate state updates to all collaborating clients in real-time.
CRDTs have strong eventual consistency, they can theoretically support any network layer capable of propagating updates from one replica to another. Given our use-case is for web applications, we are constrained to technologies supported by modern browsers- the two primary choices being WebSocket and WebRTC.
WebRTC is primarily used in peer-to-peer (P2P) topologies. Whilst WebRTC is scalable and minimises infrastructure requirements since it does not require the use of a central server, it lacks suitability for our use case.
Firstly, the majority of modern web applications already use a centralised client-server model. Companies want to retain control of data and enforce security measures such as authentication across all users, which is difficult in a P2P topology. Additionally, traversing firewalls and Network Address Translation (NAT) devices is not trivial with WebRTC- a consequence of this is that the applications will fail to propagate updates in geographies with national firewalls e.g. China.
As a result of these limitations, we chose WebSocket as the underlying protocol for our real-time infrastructure. It's support for the client-server model and stability across all major browsers made it a natural choice for us. Since WebSocket provides a bidirectional communication channel over TCP, the reliable network channel required for operation-based CRDTs is inherently provided.
Persisting Room Data
When a collaboration session ends, we need to persist room data so that room documents are not lost and users can recreate the room in the future to continue working on it.
To do this, we need to construct a data model which allows us to represent created rooms and their associated metadata. The model consists of a single Room entity:
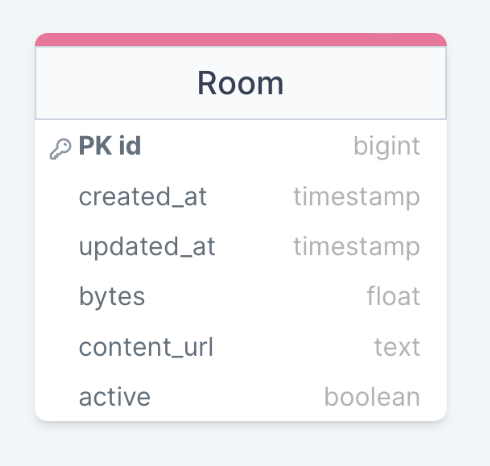
We chose to store this data in a Postgres relational database since we have a ready-heavy system and each room has a fixed schema. It also the permits analytical queries to be more easily executed. We rely on the Prisma ORM which provides a high-level, type-safe abstraction for schema creation and database interaction.
Storing Document Data
In line with Yjs best practice, we serialize room documents into a highly compressed binary format. This has the benefit of significantly reducing the amount of storage space required per document, faster data transmission and minimised bandwidth consumption across the network.
We initially thought of storing these binary blobs in the Postgres database. However, we realised that this was suboptimal.
Firstly, document sizes can become very large, particularly after lengthy collaboration sessions which can result in a large amount of accumulated CRDT metadata. Storing these documents in Postgres would affect the scalability of the database.
Secondly, Postgres is not optimized for large scale writes- the number of writes scales linearly with the number of rooms and can become particularly problematics if large documents are saved multiple times during a collaborative session. Implementing other useful features such as document versioning also becomes tricky.
One potential solution is to use a NoSQL database like AWS DynamoDB. However, these often have limits on the size of a single database item (DynamoDB has a 400kb limit), which is impractical for use cases like ours where document size can potentially be unbounded.
Considering these limitations, we decided to store documents in object storage, namely AWS Simple Storage Service (S3). Object storage is highly scalable, optimized to handle large amounts of unstructured data making it ideal for persisting schemaless room documents. It’s also cheaper than alternative NoSQL solutions like DynamoDB and supports large-scale read and write operations, making it suitable for scenarios where there is a large number of concurrent rooms and documents needs to be ingested and retrieved at high volumes. Further, our use case only requires documents to be persisted as atomic binary blobs- we do not need to query within a document making object storage more suitable than a NoSQL database.
Integrating Postgres and S3 object storage, we are now able to persist room data between collaboration sessions. When a user connects to a room, we query Postgres to determine if an existing room exists. If it does, we can retrieve the associated document from S3 and load it into memory for editing; otherwise we create a new Room record and initalize an empty document. After the last user leaves the room, we serialize the in-memory document, store it in object storage and purge the document from server memory, returning memory resource to the system.
Front-end Client API
Whilst the conflict-free data types provided by Yjs come with a primitive API, it requires the developer to have some knowledge of the underlying data model to use optimally.
In line with our design philosophy of seamlessly integrating into developers’ existing workflow, we created a JavaScript client API wrapper with sensible defaults and intuitive abstractions, through which a developer interacts with Symphony’s components.
The client exposes the conflict-free data structures including a SyncedList and SyncedMap, which are composed to form a distributed document model. Importantly, the underlying communication and persistence infrastructure, allowing the application developer to remain at a familiar level of abstraction.
The client internally implements additional quality of life improvements for the developer, provide an enhanced developer experience. These include:
- Implementing performance optimizations such as auto bulk-insertion of updates which significantly reduces memory consumption.
- Automatically converting between CRDT and plain JS objects when logical to do so such that developers do not need to keep manually converting.
- Providing undo/redo functionality with a History API. This allows undo/redo functionality to be manually paused and resumed.
- Convenience iterator methods on
SyncedListincludingfilter,map, andfind, allowing it to be used more like a regular JavaScript Array.
The full feature set provided by the Symphony client is described in our API documentation.
Load Testing
Once Symphony’s core functionality was operational, developers were able to easily create real-time collaborative applications.
However, the current architecture is limited.
The responsibility for creating, maintaining and updating state in memory for all rooms, handling user WebSocket connections, and serializing/deserializing state all fall to a single server. In other words, the system has a single point of failure.
Also, since the single server is responsible for handling all collaborative sessions and supporting the additional memory overhead resulting from our use of CRDTs, we hypothesised that whilst this architecture is suitable for a small number of rooms, it would not suffice in real-world applications that would typically have thousands of concurrent users.
To empirically verify this, we turned to load testing the system. This would also allow us to determine the system’s service level objectives (SLOs) including the concurrent user limit and identify potential bottlenecks such as compute or memory, which would later inform our scaling strategy.
Constructing a Test Environment
We first needed a way to establish a large number of virtual user connections to the server which each send state updates and broadcasted presence.
To do this, we wrote a program which spawned N separate processes, where each process modelled a virtual user connecting to the server. Since creating a large number of virtual users and propagating updates proved to be CPU intensive, we provisioned multiple EC2 instances to execute the script concurrently.
For the test itself, we selected the following load parameters.
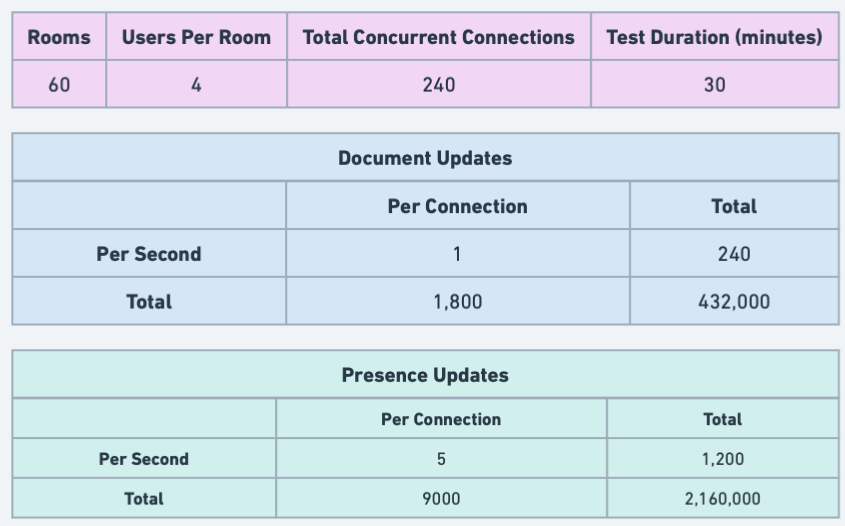
A single room server with 1vCPU and 4GB of memory, handling 240 virtual users with 4 users per room, resulting in a total of 60 rooms, propagating one state update per second and 5 presence updates per second, for a period of 30 minutes.
While the rates of document and presence updates would vary widely depending on the specific use case, we felt that these were reasonable values to model real-world usage (in comparison Liveblocks’ default settings throttle user updates to 10 per second).
Using AWS CloudWatch, we instrumented our server to extract application-level and system-level metrics including total number of WebSocket connections and CPU/memory usage.
We observed CPU usage steadily increase as a function of the number of connected virtual users. Once all connections were established, CPU usage had reached 92%. As the in-memory document size grew as a result of user updates, CPU usage peaked at 94% before we detected performance degradation in the form of dropped connections.
The results confirmed our hypothesis- that our current architecture could only handle a few hundred concurrent users for 30 minutes of real-world usage before failing.
It would be possible to vertically scale the server with greater compute and memory. However, this approach is not optimal. Firstly, the architecture would continue to have a single point of failure. Secondly, scaling would be hard-capped by the maximum instance size offered by the AWS.
For these reasons, we decided to explore horizontal scaling, which means increasing the number rather than the size of our servers. This would make our system capable of handling more users, while also being more resilient to server failures.
Scaling
Looking to Existing Solutions
Horizontally scaling the Symphony room server is not trivial. Unlike stateless services which can be scaled simply by adding more instances, clients connect to the room server via persistent WebSocket connections which are stateful. This means that clients who connect to the same room may be connected to different room server instances. This raises two problems.
The first problem is that if a client connected to a given server instance makes an update to document of a particular room on that server, then this update must be propagated to other servers which have that room document in memory; otherwise, the update will not be received by the other servers which have that room document and the state will diverge.
The second problem arises when a client attempts to connect to an already active room. It’s possible that the connecting client may be routed to a server instance which does not have the document in-memory- while the server needs a way of retrieving the most recently updated document from another server.
Redis Pub/Sub
The first problem is not unique to the Symphony room server. One common pattern to ensure updates on one server are propagated to other server is by adding a backplane, a shared component that facilitates the synchronization of data across multiple server instances.
A popular backplane is a Redis node, where each server connects to Redis channels i.e. to a ‘publish’ channel to send all updates received by the server from connected clients and to a ‘subscribe’ channel to receive all updates published by other servers. This publisher-subscribe mechanism ensures that when a client updates a room document on a particular server, the update is broadcast to all other servers- if a receiving server has the corresponding room document in memory, it can apply the update locally, ensuring that the document replicas of a given room maintain synchronised.
Querying for Documents
One way of solving the second problem, namely that the document of an active room is missing in the particular server instance that a client connect to is to retain copies of every document on each server. However, this nullifies the benefit of scaling since the memory demands on each server is not reduced.
Instead, we implemented a system where a server could query another server instance, that had the required document in memory. For this, we maintain a key-value mapping of room id’s to room server IP addresses which defines which room documents are present in which room servers. We chose AWS DynamoDB, a NoSQL key-value database to store this data.
When a client connects to a room and is routed to a server that does not have the corresponding document in memory, the server queries DynamoDB for the list of server IP addresses that are handling that room.
If one or more IP addresses are returned, it means that the room is active and thus the latest version of the document is one that is being currently edited on one or more other servers. Using one of the returned IP addresses, the server retrieves the document from the corresponding server. If no IP addresses are returned, the room is not active and the latest version of the document is simply retrieved from object storage. Once the querying server had retrieved the document, it subscribes to Redis to receive all future document updates.
This solution ensured that clients could access a room document via any server instance, without having to replicate all active room documents on every server.
Adding and Removing Instances
Since the single-server load test had identified CPU utilisation as a notable bottleneck, we set our scaling policy to target 50% CPU utilisation. This means that the system will scale out when CPU usage of any server exceeds that limit and scale in when it falls below that number.
Evaluating the Current Scaling Solution
The chosen scaling solution represents a significant improvement the single-server approach. It can support a larger number of concurrent users by elastically deploying room server instances. However, while the architecture has historically been the most prescription for scaling WebSocket-based stateful services, we found a number of significant limitations specific to our use case during load testing.
When a plurality of clients attempted to join a particular room, they were often routed to different server instances. When the number of users in each room approached the number of server instances, it would invariably lead to copies of the document being present on every server. This nullified the benefits of scaling since there was no intended decrease in memory overhead. This additional overhead was also expensive since it would lead to extraneous CPU usage as a result of updates having to be broadcast and applied at every replica. This in turn resulted in more server instanced being provisioned and additional load on the Redis node. In fact, the Redis node approached 90% CPU utilisation at a few thousand concurrent users and represented a single point failure.
These findings led us to rethink the suitability of our current architecture for our use case.
A Better Scaling Solution
Upon reflection, there are two primary problems with the Pub-Sub architecture.
The first is that there is unnecessary duplication of documents across multiple server instances. The second is that the Redis node constitutes a single point of failure.
To overcome these limitations, we took inspiration from Figma.
“Our servers currently spin up a separate process for each multiplayer document which everyone editing that document connects to.” - Evan Wallace, CTO, Figma
This approach has the advantage of keeping document state confined to a single process. This means that there is no longer a need for distributed document state, eliminating the difficulties in horizontally scaling a stateful service. Further, each process/room can be scaled independently of others resulting in minimised cost and efficient utilisation of system resources.
This improved architecture has the following requirements:
- Isolating each process/room from other rooms running on the same host.
- Dynamically orchestrating process creation, execution, and termination. Processes should also automatically be restarted in case of crashes.
- Autoscaling processes according to a specified scaling metric- in our case, this would likely be CPU or memory utilisation.
- Proxying requests to the correct service
Implementation
We arrived at the following high-level architecture.
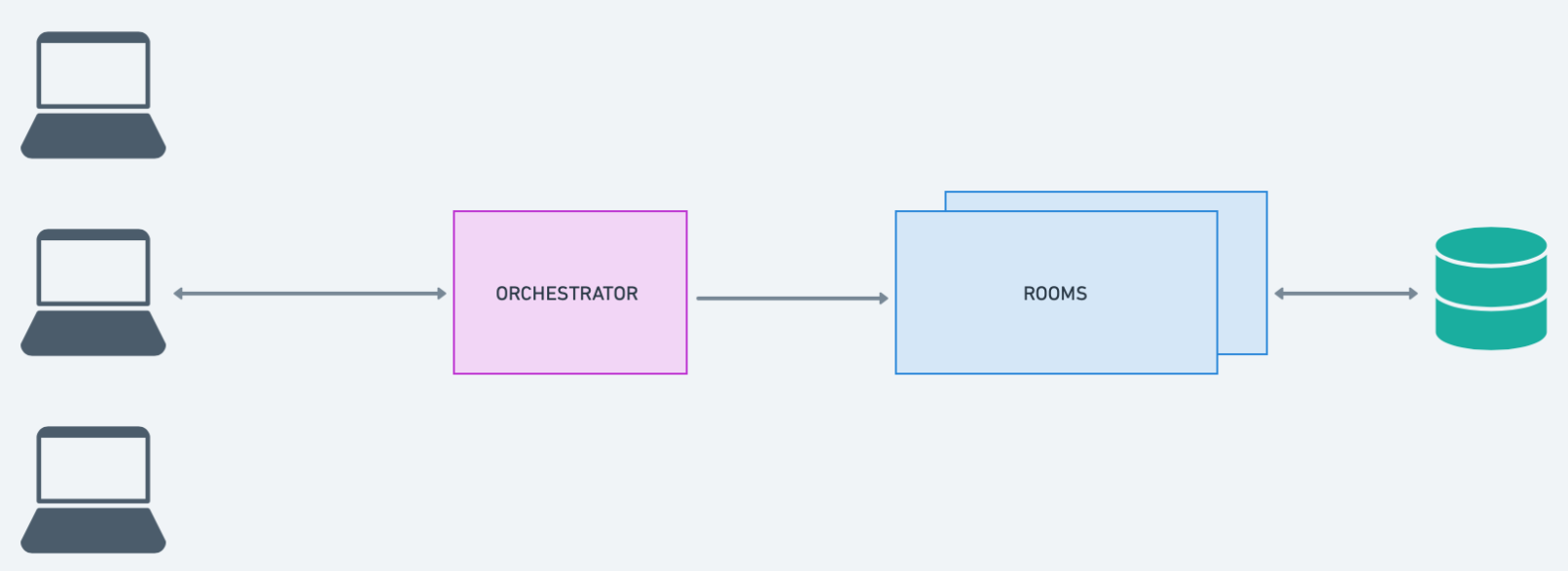
A client sends a request to connect to a room via WebSocket. As before, the client specifies the room to connect to by specifying the room ID in the URL path. The request is intercepted by a proxy server. The proxy server extracts the room ID and queries a database to check if a room process with that id is active. If there isn’t, the server requests a process, uniquely identified by room ID to be started. Once a process with the requested ID is running and ready to accept requests, a key-value record mapping the room ID to the IP address of the process is added to the database and the server proxies the client request to the relevant process and the standard collaboration session, described in Section 1 can begin.
When the last remaining client disconnects from the room, the process waits for a predefined grace period after which the process is terminated. The corresponding process record is removed from the database.
With an overall direction in mind, we then explored different options for each component of our core architecture.
Isolating Room Processes
To execute isolated room server processes, we had two potential choices of infrastructure: containers or virtual machines.
Since rooms should be ephemeral and rapidly scalable, we chose to use containers. Containers are more lightweight resulting in shorter cold start times and faster scaling. While they are less secure than virtual machine due to having a shared kernel and not providing full hardware virtualisation, this is an acceptable tradeoff for our use case since we are running trusted code.
We now needed a way of efficiently orchestrating room containers.
Orchestrating and Scaling Room Processes
One solution was to use the AWS-native way of orchestrating containers, namely AWS Elastic Container Service (ECS), as we did in our original architecture. However, we found that this suffered from considerable vendor lock-in and would make supporting multi-cloud deployment difficult in the future. Since many developers may use other cloud providers, this went against our philosophy of integrating into existing developer workflows.
Instead, we chose to use Kubernetes, a open-source container orchestration tool thanks to it’s large community, extensive tooling, and flexibility.
Serverless
Our next decision was whether to run containers in a serverless fashion or to have direct access to the virtual machines hosting the containers. In line with our design philosophy, we wanted to make it as easy as possible for developers to create real-time collaborative web applications without having to manage the underlying infrastructure. Moreover, we wanted our solution to be cost effective. Given these requirements, we chose a serverless model, where usage-based billing model i.e. per K8s pod is employed- this means that a developer will only be charged for the number of active rooms.
For hosting the cluster, we initially turned to AWS Elastic Kubernetes Service (EKS) with Fargate. However, we found a number of drawbacks to it. The most significant drawback is that EKS does not provide a fully managed option- while automated cluster creation tools such as eksctl give the illusion of a fully-managed service, it simple auto generates the required resources and does not abstract away their existence. This means that the developer is still implicitly responsible for maintaining them and may mistakenly modify the cluster configuration.
EKS also has less flexibility than other solutions. For example, EKS insists that namespaces that require Fargate compute profiles must be specified before cluster creation. If namespaces are modified in the future, it means the infrastructure configuration also needs to be changed and the cluster recreated. Thirdly, upgrading EKS clusters can be difficult- to upgrade Kubernetes version, service pods needs to be deleted so that the underlying node is destroyed and a new one with the correct Kubernetes version is created. The lack of zero-downtime upgrades adds further burden on developers.
Instead, we found that a better solution for our Kubernetes deployment was Google Kubernetes Engine (GKE) Autopilot. GKE Autopilot provides faster cluster creation, global serverless compute across all namespaces by default, and abstracts away all the underlying components such as provisioning node pools etc. from the developer, providing a cleaner developer experience.
Proxying Requests
When a client request to connect to a particular room is received via the Kubernetes Ingress, it is intercepted by the Symphony proxy service. This service has two requirements:
- Find or create the requested room service
- Proxy the request to the requested room service
To satisfy the first requirement, we query etcd to check if a service with name corresponding to the room ID exists. If it doesn’t, we send a request to the K8s API server to create a new room deployment where the service name is the room id. We then poll service endpoints in etcd until the service is marked as ready. In this case, polling was justified over a more complex mechanism such as using Kubernetes Watch since pods typically spin up within a few seconds so polling does not add much additional load. Each service has been configured with K8s readiness and liveness probes to ensure that it is not prematurely added to the list of available service endpoints and marked as healthy before the room server is ready to accept requests.
As implied by the above, we decided to use etcd as the source of truth on the existence and status of services instead of keeping a service registry cached locally- this ensures the proxy services remains stateless. Since etcd is strongly consistent, it is guaranteed to represent the true state of the system when queried. By keeping the proxy service stateless, we can horizontally scale by simply adding additional replicas without having to worry about state synchronisation. Whilst this does introduce additional latency since we need to make network calls to etcd, we decided this was a valid tradeoff as having a stateful service would radically increase complexity.
Once the required room service is ready to accept requests, the server proxies the client request to it.
Overview of the Final Architecture
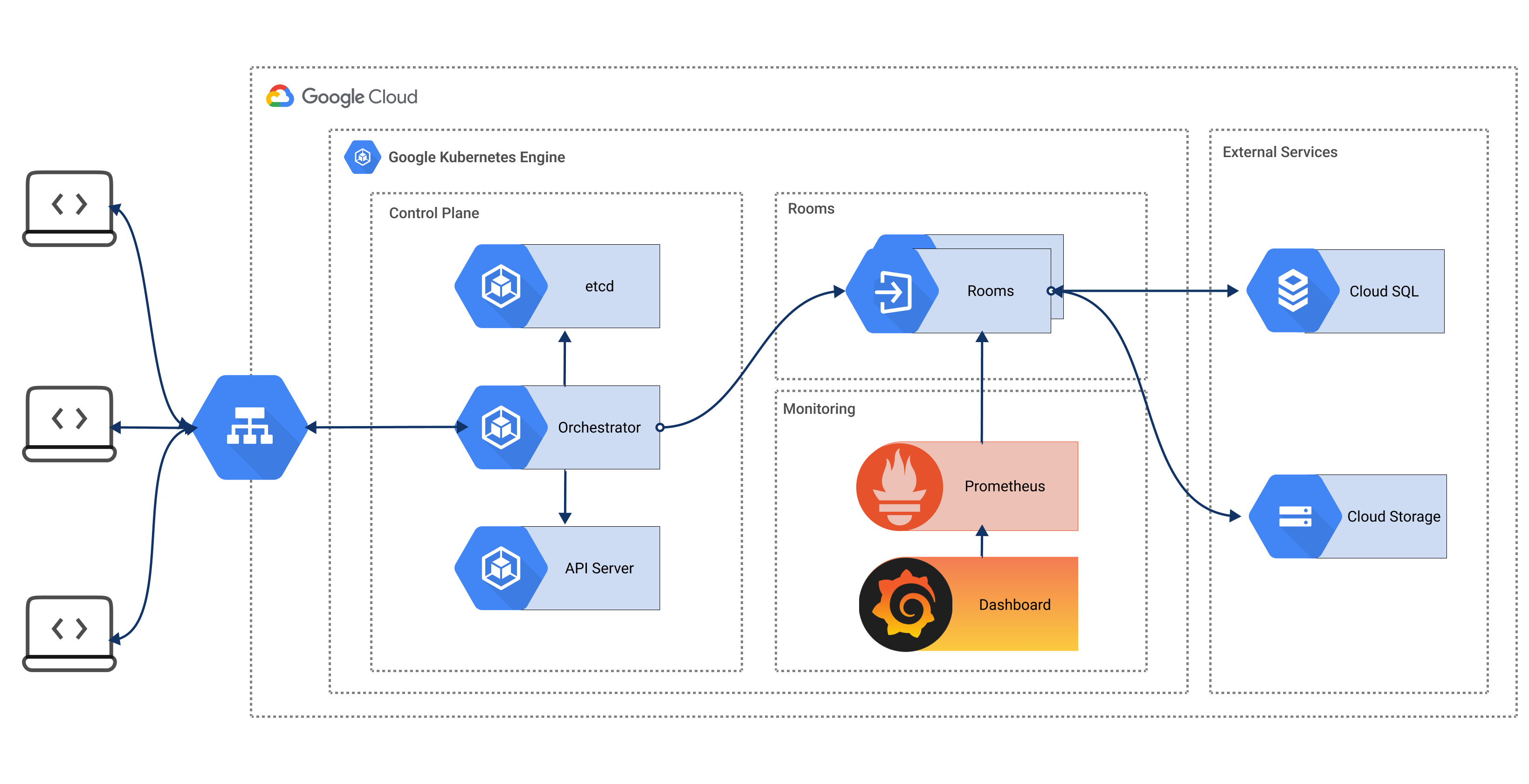
Ultimately, we settled on the following implementation for our final architecture:
- A client requests to connect to a room. The request is intercepted by the Symphony proxy.
- The proxy extracts the room id from the URL pathname and queries etcd to check if a service with that name exists.
- If the service does not exists, a request is sent to the K8s API server to create a new room deployment where the service name is the room id.
- The proxy polls etcd to check if the service is ready to accept requests. Once it is, the client request is proxied to the service.
- If the number of connections to the room remains at 0 for a specified grace period (by default 30s), the room sends a request to the K8s API server to terminate the room, returning resources back to the system.
The creation of the K8s infrastructure and the required services is automated using Terraform. We use a K8s job to automate the initialization of the database schema.
Additional Improvements
With our final architecture in place, there were a few additional considerations and features remaining for us to review. We wanted to make Symphony more performant, scalable, and secure. We also wanted to add features that would make it easier for developers to monitor the state of the system.
Monitoring and Visibility
In production applications, it’s imperative that developers have the ability to observe the usage patterns and condition of the system.
To integrate observability into Symphony, we first needed a way to scrape metrics from Symphony services, particularly room servers. We sought a flexible system that would allow us to expose and inspect large volumes of custom metrics. We chose Prometheus, an open-source, industry-standard monitoring tool that provides a variety of integrations to instrument applications and a powerful query language to querying and analyze scraped metrics.
For each room, we expose pertinent application- and system-level metrics such as the number of active WebSocket connections CPU usage and memory usage via the Prometheus client for Node.js. After provisioning the Prometheus server and configuring it to dynamically detect rooms, we deployed the Prometheus UI which allowed us to query scraped room metrics Prometheus Query Language (PromQL).
Whilst this provided satisfactory visibility, using PromQL has a small learning curve. In line with our design philosophy of creating a developer-friendly experience, we wanted the ability to visualise these metrics in an intuitive manner.
To achieve this, we integrated Prometheus with Grafana, an open-source tool that is widely used for creating interactive and customizable dashboards.
As a final touch, we created an intuitive developer dashboard UI which provides a centralised location for the developer to monitor the system. In particular, the UI provides a visualisation of room metrics that are scraped and aggregated by Prometheus in real-time as a collection of pre-configured Grafana dashboards. It also exposes historical metadata about each room by querying the Cloud SQL Postgres database such as the last time the room was active, the size of room state (bytes) per room, and the total number of rooms created (inactive + active rooms).
Reducing Pod Cold Start Time
When clients attempt to connect to a room which does not exist, the proxy must wait for the K8s scheduler to match a pod to a node and the node kubelet to run it before proxying can begin.
In certain cases, we noticed that when room deployment took as long as 2 minutes. This was surprising since K8s guarantees that “99% of pods (with pre-pulled images) start within 5 seconds” 10. After some investigation, we realised that the delay was introduced when the K8s scheduler has no available node to schedule the pod on. This resulted in a lengthy autoscaling operation until a new node was provisioned.
To mitigate this, we provisioned spare capacity using balloon pods 11. A balloon pod is a low priority (defined using a K8s PriorityClass resource) pod, which reserves extra node capacity. When a room is scheduled, the balloon pod is evicted so that the room can immediately start booting. The balloon pod is also then re-scheduled continuing to reserve capacity for the next room pod.
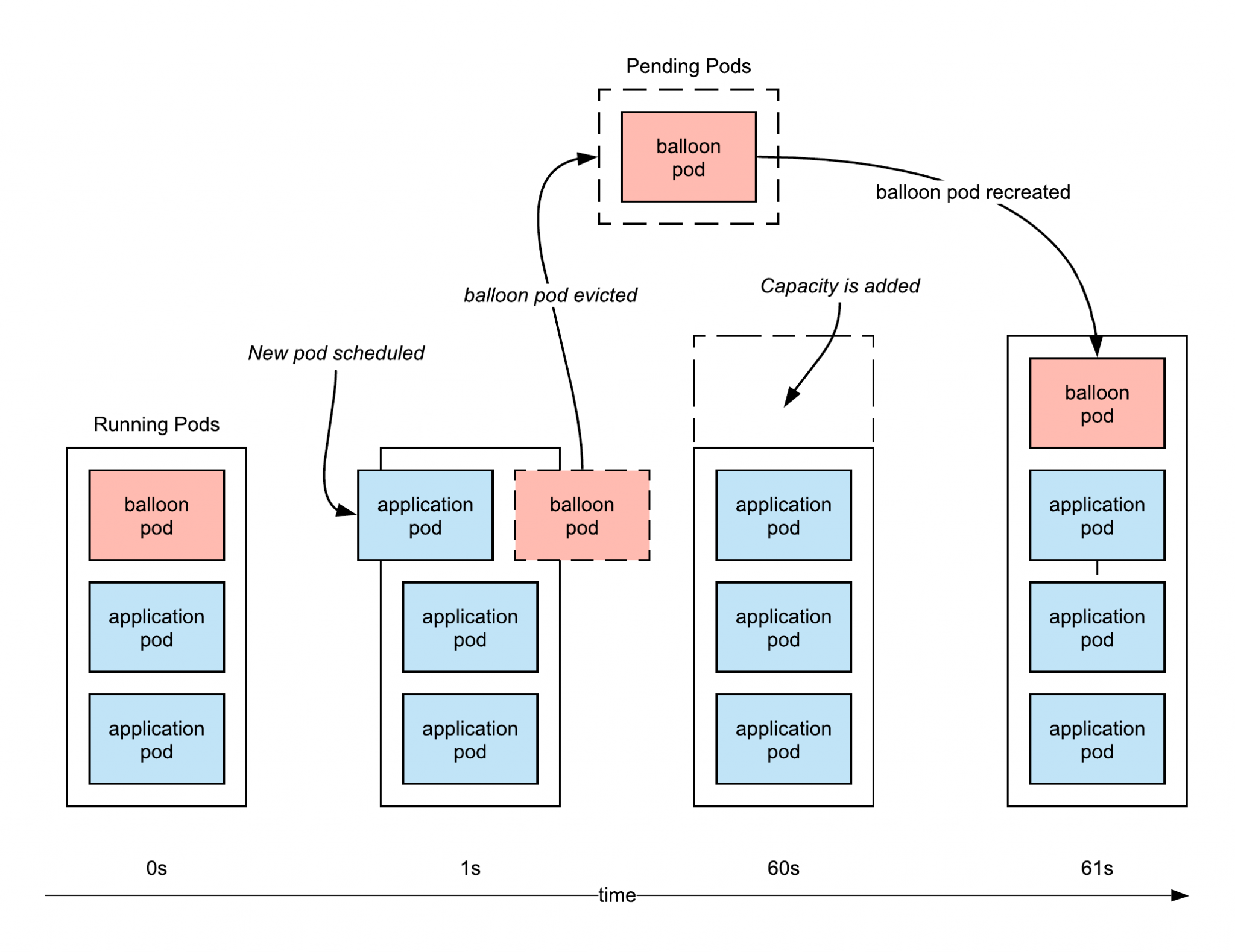
This reduced pod-startup times by 10x. Whilst this solution eliminated the problem of prolonged cold-start times, it is more expensive and the ‘always-on’ balloon pods reduces the benefit of a serverless compute layer. To minimise this disadvantage, we provision only 3 balloon pods by default, where the size of each balloon pod is equal to the size of the smallest room pod.
Securing the Deployment
To ensure our infrastructure conformed to security best practice, we added the following configurations.
Firstly, we regulated access to all K8s services in line with the principle of least privilege using Role-based access control (RBAC). We also configured Workload Identity with Google Cloud Platform (GCP) which ensures that each K8s service has least privilege when accessing GCP services external to the cluster including the database and object storage. Additionally, all non-public facing services including the Postgres database were added to private subnets to prevent direct network access.
Snapshotting
Currently, documents are only persisted to object storage once, immediately preceding room termination. This means that a process or system failure during a collaboration session would lead to irrevocable data loss, particularly given that pods are ephemeral in K8s.
To mitigate this occurrence, we implemented checkpointing, where the in-memory document is periodically serialized and persisted to object storage. This approach does, however, lead to increased costs since cloud storage has an operation-billing component, where developers are charged per use of the API. In order to balance the need to snapshot with the associated additional costs, we set the default snapshot interval to 30s i.e. in the worst-case, a user could lose 30s of work. We felt this was reasonable since a client also has a local copy which could be used to replay the state- in combination with snapshotting, this makes the system adequately fault-tolerant.
Future Work
Going forward, there are additional features that we think would enhance Symphony:
- Integrating authentication so that users can only interact with rooms they have access to.
- Expanding deployment targets beyond Google Kubernetes Engine (GKE). Since Symphony is built on Kubernetes and provisioned with Terraform, we can easily add support for other providers of K8s services include AWS EKS and Azure AKS.
- Develop a set of React hooks and providers enabling Symphony to be used declaratively.
References
- https://en.wikipedia.org/wiki/The_Mother_of_All_Demos↩
- https://erikbern.com/2017/07/06/optimizing-for-iteration-speed.html↩
- https://webrtc.org/↩
- https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API↩
- https://svn.apache.org/repos/asf/incubator/wave/whitepapers/operational-transform/operational-transform.html↩
- https://crdt.tech/↩
- https://arxiv.org/pdf/1805.06358↩
- https://www.figma.com/blog/how-figmas-multiplayer-technology-works↩
- https://www.bartoszsypytkowski.com/crdt-optimizations/↩
- https://kubernetes.io/blog/2015/09/kubernetes-performance-measurements-and/#:~:text=“Pod↩
- https://wdenniss.com/gke-autopilot-spare-capacity↩